MLOps
In addition to implementing automatic model retraining, my project fully adheres to the best practices of MLOps.
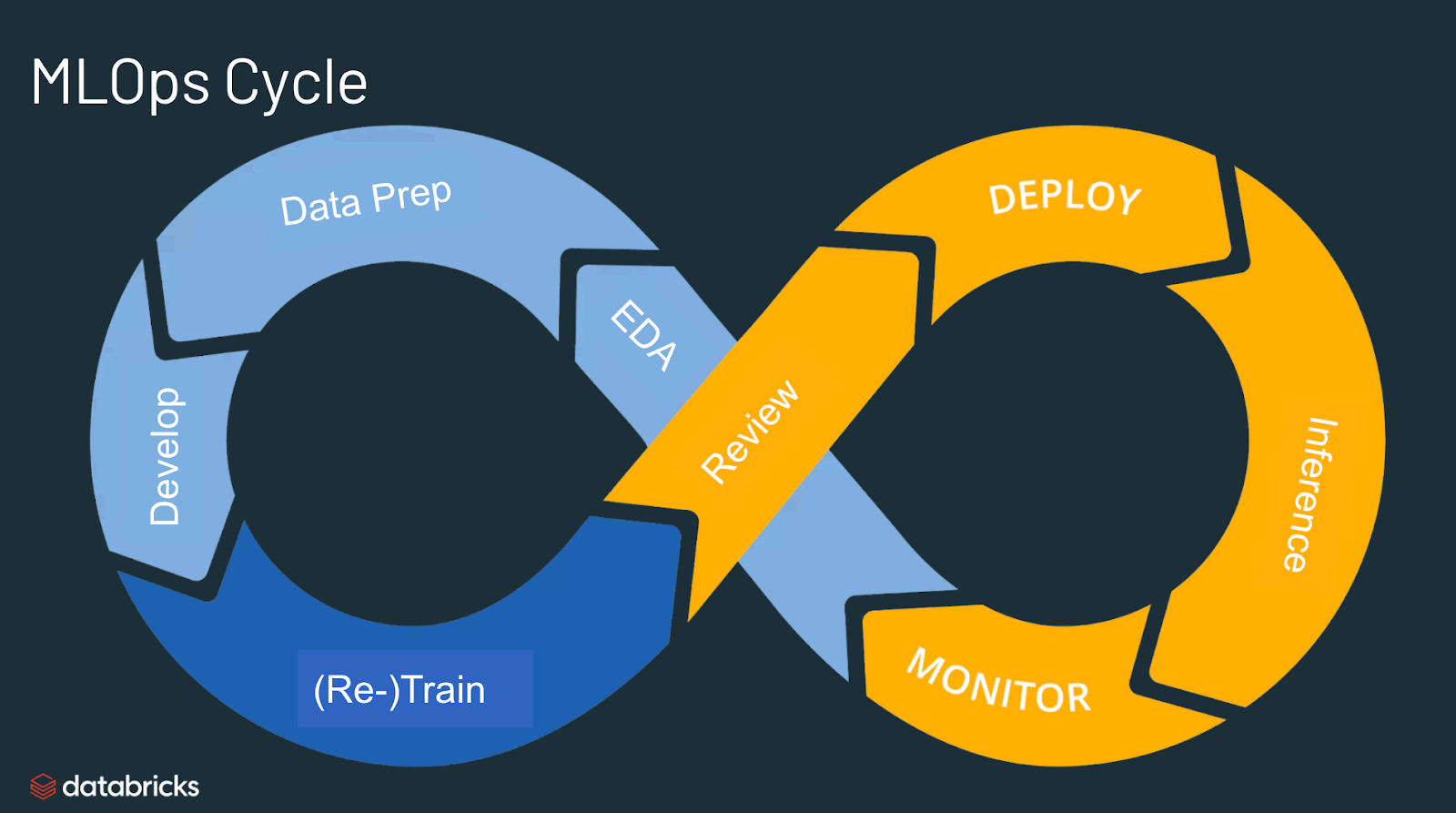
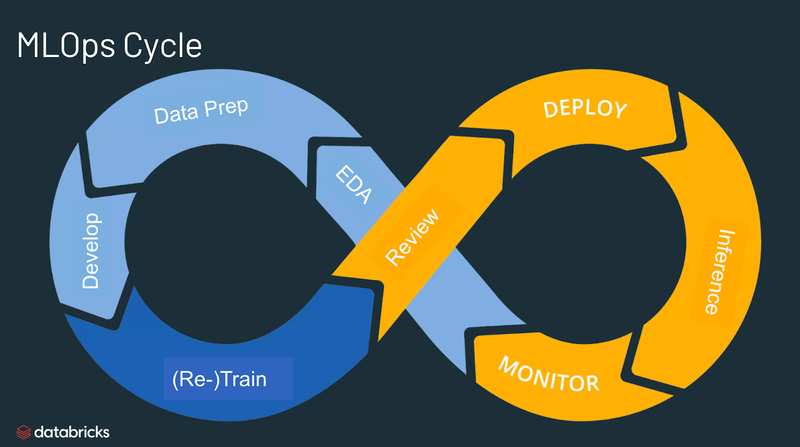
Best practices for MLOps
The best practices for MLOps can be delineated by the stage at which MLOps principles are being applied.
- Exploratory data analysis (EDA) - Iteratively explore, share, and prep data for the machine learning lifecycle by creating reproducible, editable, and shareable datasets, tables, and visualizations.
- Data Prep and Feature Engineering- Iteratively transform, aggregate, and de-duplicate data to create refined features. Most importantly, make the features visible and shareable across data teams, leveraging a feature store.
- Model training and tuning - Use popular open source libraries such as scikit-learn and hyperopt to train and improve model performance. As a simpler alternative, use automated machine learning tools such as AutoML to automatically perform trial runs and create reviewable and deployable code.
- Model review and governance- Track model lineage, model versions, and manage model artifacts and transitions through their lifecycle. Discover, share, and collaborate across ML models with the help of an open source MLOps platform such as MLflow.
- Model inference and serving - Manage the frequency of model refresh, inference request times and similar production-specifics in testing and QA. Use CI/CD tools such as repos and orchestrators (borrowing devops principles) to automate the pre-production pipeline.
- Model deployment and monitoring - Automate permissions and cluster creation to productionize registered models. Enable REST API model endpoints.
- Automated model retraining - Create alerts and automation to take corrective action In case of model drift due to differences in training and inference data.
https://www.databricks.com/glossary/mlops